|
Cloud and Mobile-based System for Processing High Volume Field Service Work Orders |
||
|
Yan Zang 2/19/2010
Copyright Harmonisoft
Inc. |
||
| Summary | ||
|
The present article describes a work order management system that shares information in real-time within a multi-tiered network of processors, and efficiently process work orders of high volume. |
||
| Abstract | ||
|
Methods and systems are developed to process high volume service work orders that flow through a network of distributed, and multi-tiered field service processors. Service information is made available in real-time via the internet among order issuers, regional contractors, and individual field workers, in geographically distributed locations. A relational data structure is developed to manage the multi-tiered and dynamic relationships among processors. Data partitions are developed to allow fast access to the most current data and isolate existing users from increasing amount of data. A queuing method is developed to handle spiking demand on network bandwidth and computer servers by distributing work requests to multiple computing and storage resources and processing them asynchronously. |
||
| Background | ||
|
Many field service industries routinely process work orders of high volume. The orders, originated by order issuers, are dispatched to regional contractors who in turn distribute them to subcontractors and individual field workers. After work orders are fulfilled in the field, field workers submit them to contractors, who then submit them back to the order issuers. The work orders are required to be completed and submitted back to order issuers within a specified time period. The various processors in this workflow are located in geographically distributed locations. There is therefore a need to develop a system to automate the flow of the work orders so that they can be processed in a timely manner and satisfy various requirements on the orders' fulfillment. Traditional client-server software systems distribute work orders from remote computer servers to software that is installed on user's desktop computer. The need to transfer and synchronize work order data between remote servers and users' desktop computers is prune to errors. It is desirable to make the work order information shared by all processors in real time. There is an additional need to manage the multi-tiered and dynamic relationships among work order processors. There can be multiple tiers of customer and vendor relations, between order issuers, contractors and multiple levels of subcontractors. These relationships can also change over time. For example, company A has company B and company C as contractors, while company B has company C and D as contractors. At a later time, company D may become a direct contractor of company A while terminating its relationship with company B. A flexible relational structure is therefore required to manage this complex and dynamic relationship. There is a further need to handle flows of large volumes of service work orders. Both the accumulation of historic data as well as the addition of new users bringing in more work orders add load to the database, making data access increasingly slow. When the amount of data reaches a certain level, the database ceases to function effectively. Methods are needed to allow processors to quickly access the most current work order data. Methods are also needed to isolate existing users from the impact of increasing amount of new data coming into the system. In dispatching work orders, it is not uncommon for an order issuer to dispatch the whole volume of a month's work orders on a single day. This creates a spiking demand on network bandwidth and computer servers that can be many times higher than normal. Methods are therefore needed to efficiently handle spiking demand in a relatively short period of time, while still cost-effectively manage normal work order volume on a daily basis. |
||
| Description of the System | ||
|
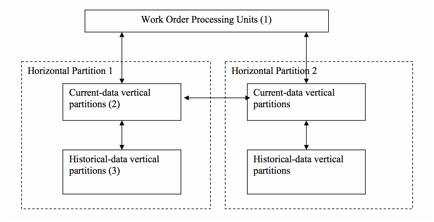
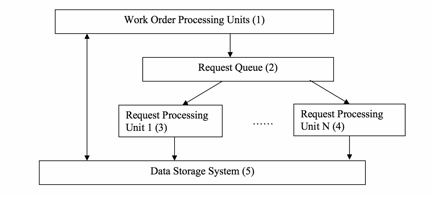
Objects of developing the present system include (1) to create systems and methods to allow real-time information sharing among work order processors, (2) to develop a flexible data structure to manage the multi-tiered, dynamic relationships among work order processors, (3) to develop a system to process work orders in high volume, and (4) to develop methods to efficiently handle unusually high, spiking demand on network and computer servers in a relatively short period of time, while cost-effectively process normal flow of work orders. The present field service management system, EZ Inspections & Preservation (www.ezinspections.com), based on the cloud and mobile-based computing, is developed to process work orders of high volume. The work order data and attachment files are stored on computer servers and are made available to all processors - order issuers, regional contractors and field workers. Each processor is given credentials to log into the servers and can only access the portion of the data to which the processor has permission. The processor accesses work order information using an internet browser or a mobile device. A single copy of the work order is shared and updated by multiple processors, eliminating the need of data transfer and synchronization between servers and processors' desktop computers. Relationships between processors are built using a relational data structure. Each processor has its own information stored in a database table. An additional database table is developed to store relationships between processors. This data structure enables building of relationship between any two users in the system. Furthermore, the relational data structure allows for unlimited tiers of customer-vendor relationships. When change in relationship occurs between processors, the change can be easily implemented by updating the relational data structure. In order to handle increasing amount of work order data, either from the accumulation of historical data or from the addition of new user data, the data structure is partitioned both horizontally and vertically to provide better data access performance. Horizontal partition refers to dividing work order data by system users. Each horizontal partition only holds a portion of all the system users. The allocation of users into horizontal partitions is determined by user relationships that are stored in the relational data structure discussed above. The most frequent data access and exchange is carried out within a user's own partition, while inter-partition data transfer is conducted for less frequent operations. The horizontal partition isolates existing users from the impact of addition of new user data. Vertical partition refers to dividing work order data by the time that work orders are completed. In work order processing, the vast majority of users' data accesses are to the data that is most recently created, while accessing data that is over several months old is relatively rare. The system described here regularly moves historical data to separate data structures, thus improving access speed to the current data. Horizontal and vertical partitions of data can be either stored on the same computer server or database, or distributed and stored on multiple computer servers or databases. A queuing mechanism is developed to asynchronously process work order requests. When an unusually large number of processing requests are received by the system, especially during a short period of spiking load, instead of processing the requests synchronously and potentially creating a bottleneck, the current system creates a queue for the requests. The queued requests are distributed to one or more request processing units and are processed asynchronously. New instances of the request processing units can be started to process additional requests if needed. This queuing and asynchronous processing improves the overall performance of the current system. |
||
| Brief Description of the Drawings | ||
|
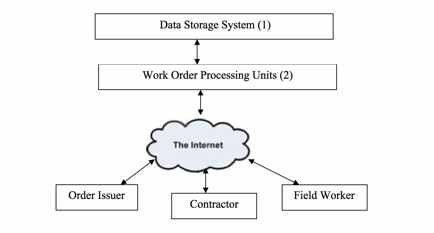
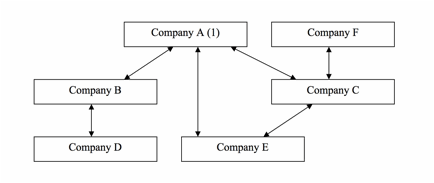
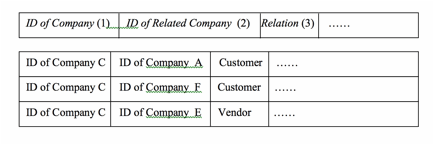
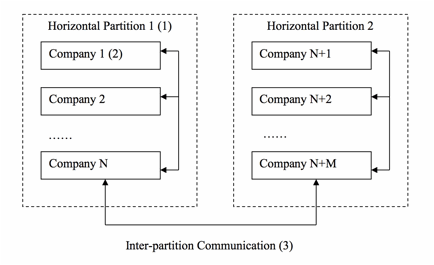
Fig. 1 is a sketch displaying that all processors share the same data in the field service work order processing. Fig. 2 is the preferred relational structure of processors in accordance with the principles of the present system Fig. 3 is the preferred relational database design for handling processor relations in accordance with the principles of the present system Fig. 4 is a sketch of horizontal partition of work order data in accordance with the principles of the present system Fig. 5 is a sketch of the vertical partition of work order data in accordance with the principles of the present system Fig. 6 is a sketch of the queuing mechanism to asynchronously handle spiking demand on system resources in accordance with the principles of the present system |
||
| Detailed Description of a Preferred Implementation | ||
|
A cloud and mobile-based computer software system is developed to process high-volume work orders. Specifically the computer software system is developed for processing field service work orders. Turning to Fig. 1, all the data and file attachments related to work orders are stored in one data storage system (1) that can be shared by all the work order processors. Work order data is stored in one or more relational databases. File attachments are stored in one or more hard disk arrays in a file storage system. The relational databases and file storage system is collectively called 'data storage system' Data and file attachments are retrieved and processed by the work order processing units (2) which are one or more computer servers. The data storage system and work order processing units are hosted in a cloud-computing facility. The processors in the work flow, order issuers, contractors and field workers, access their data and file attachments through the internet using internet browsers. Requests of data access are processed by the work order processing units and updates are made to the data storage system. Updates performed by any processor can be retrieved by other processors in real-time through accessing the same data storage system. Fig. 2 depicts the preferred relational structure among processors in the work flow. Unlike traditional designs that pre-define the role of a processor as order issuer, contractor, or individual field worker, the current design defines each processor as the same entity 'Company' (1). This way, the same data structure applies to all processors. If a processor changes its status, for example, from an individual worker to a contractor that hires other individual field workers, there is no need to change its data structure. The relations between processors are defined by a database table 'CompanyRelation' . As depicted in Fig. 3, each relation is defined in this table by the identifier of a company (1), the identifier of its related company (2), and their relationship (3). The relationship can be 'Customer', 'Vendor', or other codes defining the relations between two processors. The data structure in Fig. 3 allows for unlimited tiers of customer-vendor relations. In addition, the data structure in Fig. 3 facilitates easy handling of changing relations between processors. Changes can be made simply by adding records into CompanyRelation table for new relations, deleting terminated relations, or updating the Relation field (3) for changed relations . When handling high-volume work orders, system performance can be improved if the work order data is divided into smaller partitions. Fig. 4 depicts a preferred way in the current xyxtem to partition work order data 'horizontally'. Each horizontal partition (1) holds a number of processor companies (2), containing preferably companies and their networks of vendors and customers. The data in each partition is handled by one or more databases. Data communication within a partition is more efficient than data communications between partitions. System performance can be significantly improved because the amount of data in each partition is only a fraction of the whole work order data. Performance is additionally improved because vast majority of data communications occur among processor companies and their vendors and customers; these communications are handled by the more efficient data operations within partitions. Communication between partitions, or 'inter-partition' communication (3), represents data transfer between a company and other companies that are outside of its network. This type of communication is relatively rare, and has a smaller impact to the overall performance of the system. In another preferred embodiment of the current design, work order data can be partitioned 'vertically' by separating historical data from 'current data' - the data that is most recently created. Fig. 5 depicts such a design. While historical data is accessed less frequently, its accumulation can degrade system performance if it is stored together with current data. In the preferred embodiment depicted in Fig. 5, data is separated into current-data partitions (2) and historical-data partitions (3). Work order processing units (1), which process user requests and hand them over to the data storage system, only interface with current-data vertical partitions (2). If a user request is made to access historical data, the historical data is first retrieved from its historical-data vertical partition (3) into a current-data vertical partition (2) before being transmitted to the user. When both horizontal and vertical partitions are utilized, vertical partitions of current data and historical data are created within each horizontal partition. Inter-partition data communications between horizontal partitions only involve current data while historical data is first moved into the current-data vertical partition before it is transferred outside of a horizontal partition. In work order processing, it is not uncommon that a unusually large number of requests of certain kind can occur during a relatively short period of time, thus creating high and spiking heavy demand on network bandwidth and computer servers. Examples of these requests include importing a large number of work orders into the system, or downloading or printing out a large number of work orders from the system. Processing these requests synchronously can create a bottleneck and prevent the system from effectively handling other types of requests that may be of a more urgent nature. Fig. 6 depicts a preferred embodiment of the current system in which a queuing mechanism is developed to handle this kind of spiking demand. When certain types of user requests occur at the system, the work order processing units (1), which are typically application servers, create tasks for these requests and put them in one or more queues (2). The requests are processed asynchronously by one or more request processing units (3) and (4) that can be either the same as or different from those units (1) handling normal user requests. The maximum number of concurrent requests that are being processed by each processing unit is pre-determined in order to avoid system bottleneck. New instances of request processing unit (3) can be created or terminated to process varying volume of requests. When a queued task is completed, the data storage system (5) is updated. User can access the data storage system to monitor the progress and status of the queued tasks. This design removes the potential bottleneck created by spiking volume of user requests, and allows users to continue performing other tasks while waiting for the queued tasks to be completed. |
||
| Drawings | ||
|
||
| About the Author | ||
|
Yan Zang is the founder and president of Harmonisoft Inc., which owns and operates EZ Inspections and Preservation, the leading cloud and mobile-based inspection and property preservation software system . EZ was launched in 2005 and grew to serve 40,000 users in multiple field service industries and process over 8 million work orders a year. Before founding Harmonisoft, Yan spent eight years in Silicon Valley serving in engineering and management positions in multiple high-tech companies in the fields of mechanical engineering, electrical engineering and computer software. Yan graduated from Peking University in Beijing, China, and received his M.S. from Rutgers University in New Jersey, and his Ph. D. from Stanford University in California. Contact Yan at yan@ezinspections.com. For more related topics, check out EZinspections.com articles on inspection software and property preservation management system . |
||